

State of the Art: Object detection (2/2)
This article is a continuation of the work done in the previous article. It will summarize other methods used by the best COCO ranking architectures such as YOLOR, CBNet and R-CNN series, CenterNet, DetectoRS and EfficientDet.
Table of contents
- YOLOR
- CBNet
- R-CNN
- Fast R-CNN
- Faster R-CNN
- Mask R-CNN
- Cascade R-CNN
- Cascade Mask R-CNN
- CBNet: A Novel Composite Backbone
- CenterNet
- CornerNet
- CenterNet
- DetectoRS
- EfficientDet
- Conclusion
1) YOLOR
In their paper, the authors proposed a unified network to encode implicit knowledge and explicit knowledge together, just like the human brain can learn knowledge from normal learning as well as subconsciousness learning. The unified network can generate a unified representation to simultaneously serve various tasks.
The results demonstrate that when implicit knowledge is introduced into the neural network, it benefits the performance of all tasks.
They call explicit knowledge the knowledge that directly correspond to observation. Implicit knowledge is for the knowledge that has nothing to do with observation. Their unified network is shown in the Figure 2:

Kernel Alignment: They also perform Kernel alignment with addition and multiplication of output feature and implicit representation, so that Kernel space can be translated, rotated, and scaled to align each output kernel space of neural networks:
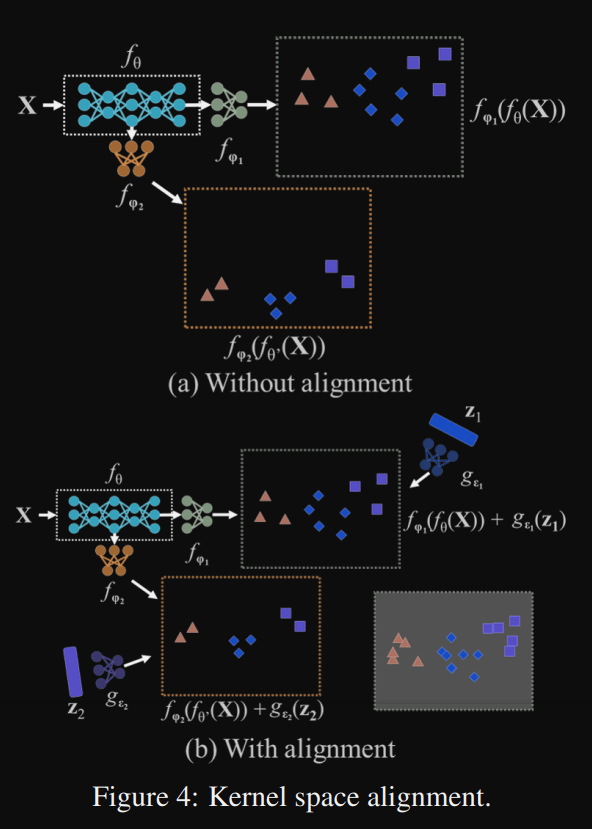
Relax Loss: In traditional training, we expect different observations with the same target to be a single point in the sub space obtained by the model. In their paper, they introduced a “relax error” to make it possible to find solution of each task at the same time on manifold space:

This is achieved with addition, multiplication, and concatenation of the explicit error and implicit error.
Selective Kernel: this method, shown in Figure 2, which allows the network to choose between two kernels with a softmax attention mechanism, is very interesting. The author of the Selective Kernel paper states that:
It is well-known in the neuroscience community that the receptive field size of visual cortical neurons are modulated by the stimulus, which has been rarely considered in constructing CNNs. We propose a dynamic selection mechanism in CNNs that allows each neuron to adaptively adjust its receptive field size based on multiple scales of input information

The authors of YOLOR showed that their unified network, which integrates implicit and explicit knowledge, is effective for multi-task learning under the single model architecture.
2) CBNet
First, we will do a quick review of the R-CNN series: R-CNN, Fast R-CNN, Faster R-CNN, Mask R-CNN, Cascade R-CNN, Cascade Mask R-CNN. Next, we will move on to the CBNet paper which applies its method to Cascade Mask R-CNN.
2-1) R-CNN
R-CNN uses selective search to determine ROIs (regions of interest) considered candidates for object detection. It extracts around 2k region proposals, computes features for each region with a CNN to finally classify them using SVMs.
Its training is a multi-stage pipeline. R-CNN first finetunes a ConvNet on object proposals using log loss. Then, it fits SVMs to ConvNet features. These SVMs act as object detectors, replacing the softmax classifier learnt by fine-tuning. In the third training stage, bounding-box regressors are learned.
R-CNN is slow because it performs a ConvNet forward pass for each object proposal, without sharing computation.
2-2) Fast R-CNN
Section 2 of the paper is a good summary of the improvement to the original R-CNN:
Fast R-CNN network takes as input an entire image and a set of object proposals. The network first processes the whole image with several convolutional (conv) and max pooling layers to produce a conv feature map. Then, for each object proposal a region of interest (RoI) pooling layer extracts a fixed-length feature vector from the feature map. Each feature vector is fed into a sequence of fully connected (fc) layers that finally branch into two sibling output layers: one that produces softmax probability estimates over K object classes plus a catch-all “background” class and another layer that outputs four real-valued numbers for each of the K object classes. Each set of 4 values encodes refined bounding-box positions for one of the K classes.
2-3) Faster R-CNN
A good summary of Faster R-CNN can be found on the following page:
Faster R-CNN is an object detection model that improves on Fast R-CNN by utilising a region proposal network (RPN) with the CNN model. The RPN shares full-image convolutional features with the detection network, enabling nearly cost-free region proposals. It is a fully convolutional network that simultaneously predicts object bounds and objectness scores at each position. The RPN is trained end-to-end to generate high-quality region proposals, which are used by Fast R-CNN for detection. RPN and Fast R-CNN are merged into a single network by sharing their convolutional features: the RPN component tells the unified network where to look.
2-4) Mask R-CNN
Mask R-CNN add a branch to Faster R-CNN for predicting an object mask.
It also had to implement a RoiAlign to ensure a pixel-to-pixel alignment between network inputs and outputs.
Instead of predicting a pixel-wise label, Mask R-CNN predicts binary masks and relies on the on the network’s RoI classification branch to predict the category.
2-5) Cascade R-CNN
Cascade R-CNN is an extension of the multistage R-CNN. It aims to solve the problem of training with fixed thresholds of 0.5 IoU that typically produce noisy detections. With higher thresholds, the performance of the model usually decreases due to overfitting caused by exponentially disappearing positive samples.
To solve this problem, the stages are trained sequentially using the output of the previous stage and with higher IoU thresholds to be sequentially more selective. The resampling of progressively improved hypotheses guarantees that all detectors have a positive set of examples of equivalent size, reducing the overfitting problem.
2-6) Cascade Mask R-CNN
Cascade Mask R-CNN add a mask head to the Cascade R-CNN to enable instance segmentation.
Three different strategies are proposed:
- the first two strategies add a single mask prediction head at either the first or last stage of the Cascade R-CNN. The instances used to train the segmentation branch are the positives of the detection branch: placing the segmentation head later on the cascade leads to more examples,
- The third strategy adds a segmentation branch to each cascade stage. This maximizes the diversity of samples used to learn the mask prediction task.
2-7) CBNet: A Novel Composite Backbone
In the CBNet paper, the authors propose a novel strategy for assembling multiple identical backbones by composite connections between the adjacent backbones, to form a more powerful backbone named Composite Backbone Network (CBNet).
It iteratively feeds the output features of the previous backbone, namely high-level features, as part of input features to the succeeding backbone, in a stage-by-stage fashion, and finally the feature maps of the last backbone (named Lead Backbone) are used for object detection:

They applied their method to Cascade Mask R-CNN to achieve their results of 53.3 on COCO dataset.
3) CenterNet
In the CenterNet paper, the authors use CornerNet as an example of the application of their method.
3-1) CornerNet
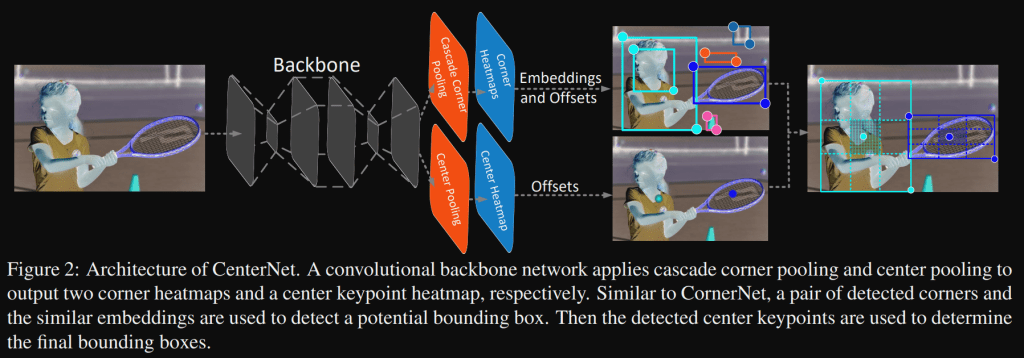
CornerNet detects an object bounding box as a pair of keypoints, the top-left corner and the bottom-right corner, using a single convolution neural network. By detecting objects as paired keypoints, it eliminates the need for designing a set of anchor boxes commonly used in prior single-stage detectors.
It produces two heatmaps (top-left and bottom-right corners). The heatmaps represent the locations of keypoints of different categories and assigns a confidence score for each keypoint. Besides, it also predicts an embedding and a group of offsets for each corner:
- The embeddings are used to identify if two corners are from the same object,
- The offsets learn to remap the corners from the heatmaps to the input image.
For generating object bounding boxes, top-k left-top corners and bottom-right corners are selected from the heatmaps according to their scores. Then, the distance of the embedding vectors of a pair of corners is calculated to determine if the paired corners belong to the same object (distance < threshold). The bounding box is assigned a confidence score, which equals to the average scores of the corner pair.
In the CenterNet paper, the authors state that CornerNet suffers from False Discovery: in average, 32.7% of object bounding boxes have IoU lower than 0.05 with the ground-truth. This could be caused by the fact that it cannot look into the regions inside the bounding boxes. Using ROIs with a two stage detector could solve the issue by its expensive. The CenterNet authors developed a method that aims to be a highly efficient alternative to explore the visual patterns within each bounding box. For detecting an object, their approach uses a triplet, rather than a pair, of keypoints. By doing so, their approach is still a one-stage detector, but partially inherits the functionality of RoI pooling.
3-2) CenterNet
This method represents each object by a center keypoint. They embed a heatmap for the center keypoints on the basis of CornerNet and predict the offsets of the center keypoints. To filter out the incorrect bounding boxes, they leverage the detected center keypoints and resort to the following procedure:
- select top-k center keypoints according to their scores,
- use the corresponding offsets to remap these center keypoints to the input image,
- define a central region for each bounding box and check if the central region contains center keypoints with the same class label,
- if a center keypoint is detected in the central region, we will preserve the bounding box.
They proposed a scale-aware central region to adaptively fit the size of bounding boxes.
The scale-aware central region tends to generate a relatively large central region for a small bounding box, while a relatively small central region for a large bounding box:

They set to be 3 and 5 for the scales of bounding boxes less and greater than 150, respectively. This implements a scale-aware central region to validate a prediction if the central region contains center keypoints.
To create the bounding boxes, two issues are pointed out by the authors:
- Center keypoints: the geometric centers of objects do not necessarily convey very recognizable visual patterns, for instance, for a human body detection, strong patterns can be on the face. To solve this issue, they proposed a center pooling to capture richer and more recognizable visual patterns.
- Corner keypoints: corners are often outside the objects, which lacks local appearance features. CornerNet uses corner pooling to address this issue but it makes corners sensitive to the edges and it does not let corners “see” the visual patterns of objects. CenterNet proposed a cascade corner pooling to solve this issue.
Both methods are illustrated:

The center pooling module takes a maximum value in a direction, e.g., the horizontal direction, it connects a left pooling and a right pooling in series. The cascade top corner pooling module, compared with the top corner pooling in CornerNet, adds a left corner pooling before the top corner pooling:

To train the model, they used a loss with 6 parts:
- Two focal losses to detect corners and center keypoints,
- A “pull” loss for corners, which is used to minimize the distance of the embedding vectors that belongs to the same objects,
- A “push” loss for corners, which is used to maximize the distance of the embedding vectors that belongs to different objects,
- Two l1-losses to train the network to predict the offsets of corners and center keypoints.

4) DetectoRS
DetectoRS has two main innovations:
- At the macro level, their authors propose Recursive Feature Pyramid (RFP), which incorporates extra feedback connections from Feature Pyramid Networks into the bottom-up backbone layers,
- At the micro level, they propose Switchable Atrous Convolution, which convolves the features with different atrous rates and gathers the results using switch functions:

Inspired by the human vision system, the mechanism of looking and thinking twice has been instantiated in computer vision, and demonstrated outstanding performance. Many popular two-stage object detectors, e.g., Faster R-CNN, output object proposals first, based on which regional features are then extracted to detect objects…The success of this design philosophy motivates us to explore it in the neural network backbone design for object detection.
They obtained a backbone that looks at the images twice or more to generate increasingly powerful representations. The feedback connections bring the features that directly receive gradients from the detector heads back to the low levels of the bottom-up backbone to speed up training and boost performance. This Recursive Feature Pyramid can be illustrated with a two steps sequential network:

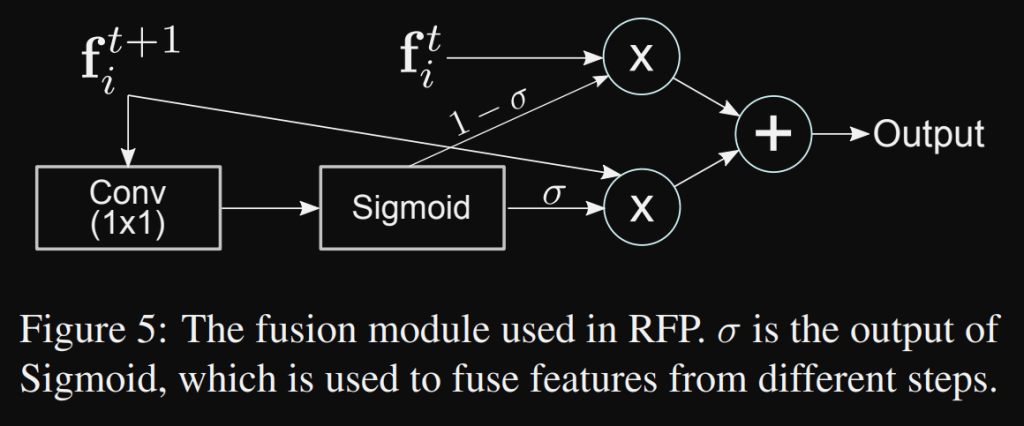
Atrous convolution is an effective technique to enlarge the field-of-view of filters at any convolutional layer. In particular, atrous convolution with atrous rate r introduces r − 1 zeros between consecutive filter values, equivalently enlarging the kernel size of a k × k filter to [k + (k − 1)(r − 1)] without increasing the number of parameters or the amount of computation. Fig. 1b shows an example of a 3×3 convolutional layer with the atrous rate set to 1 (green) and 2 (mauve): the same kind of object of different scales could be roughly detected by the same set of convolutional weights using different atrous rates.
Their Switchable Atrous Convolution (SAC) is illustrated with the following figure:

DetectoRS has been tested on COCO for object detection, instance segmentation and panoptic segmentation. It obtained new state-of-the-art results for all these tasks.
5) EfficientDet
In the EfficientDet paper, the authors studied neural network architecture design choices for object detection and propose several key optimizations to improve efficiency.
First, they proposed a weighted bi-directional feature pyramid network (BiFPN), which allows easy and fast multiscale feature fusion; Second, they proposed a compound scaling method that uniformly scales the resolution, depth, and width for all backbone, feature network, and box/class prediction networks at the same time.
EfficientDet-D7+ achieves state-of-the-art 55.1 AP on COCO test-dev with 77M parameters and 410G FLOPs, being 4x – 9x smaller and using 13x – 42x fewer FLOPs than previous detectors.
They built a scalable detection architecture to accommodate a wide spectrum of resource constraints: from 2.5G to 410G Flops with 34.6 to 55.1 AP on COCO test-dev divided into 8 versions.
For an efficient multi-scale feature fusion, they proposed a weighted bi-directional feature pyramid network (BiFPN), which introduces learnable weights to learn the importance of different input features (instead of doing a simple summation).
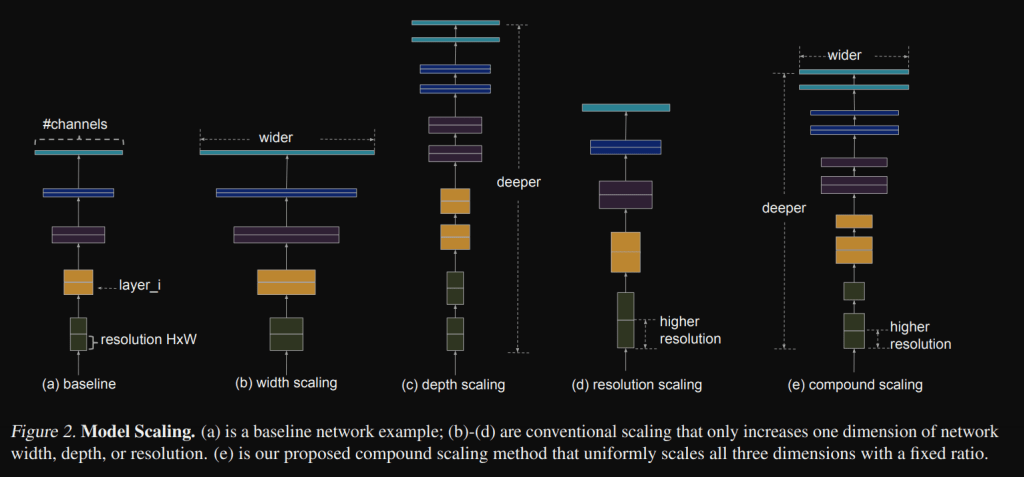
While previous works mainly rely on bigger backbone networks or larger input image sizes for higher accuracy, they observed that scaling up feature network and box/class prediction network is also critical when taking into account both accuracy and efficiency. They proposed a compound scaling method for object detectors, which jointly scales up the resolution/depth/width for all backbone, feature network, box/class prediction network.
They finally combined their EfficientNet backbones with they proposed BiFPN and compound scaling to create the EfficientDet family.

The authors studied a regular FPN (a), the extra bottom-up path aggregation network of PANet (b), and the neural architecture “search to search” of NAS-FPN which is expensive and produce irregular networks, difficult to interpret or modify. They observed that PANet achieves better accuracy than FPN and NAS-FPN, but with the cost of more parameters and computations. To solve this issue, their removed the nodes that only have one input edge (layer 2: P3 and P7). They also added edges from input 4-5-6 to output.
They also observed that since different input features are at different resolutions, they usually contribute to the output feature unequally. To address this issue, they proposed to add an additional weight for each input, and let the network to learn the importance of each input feature. This can be done with 3 strategies (the last one is the one used):
- Unbounded fusion: learnable weight that can be a scalar (per-feature), a vector (per-channel), or a multi-dimensional tensor (per-pixel),
- Softmax-based fusion: the idea is to apply softmax to each weight, such that all weights are normalized to be a probability with value range from 0 to 1, representing the importance of each input, however this leads to significant slowdown on GPU hardware,
- Fast normalized fusion: the values are also normalized between 0 and 1, but without a softmax operation, it is much more efficient:
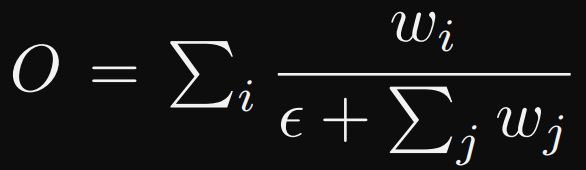
The P6_out formula becomes:


They also used depthwise separable convolution for feature fusion, and added batch normalization and activation after each convolution.
Finally, to scale their architecture they proposed a new compound method with a coefficient from 0 to 7. This coefficient is used:
- To linearly increase the Width and Depth of their BiFPN network following:

2. To linearly increase the Depth of the Box/class prediction network:

3. To linearly increase the Depth of the input image resolution:

The architecture is illustrated in the following figure:

The versions hyper-parameters are shown in the next table:

Note: Backbone network is explained in the EfficientNet paper, this network from the same authors also has a scaling strategy on the depth, width and input resolution:
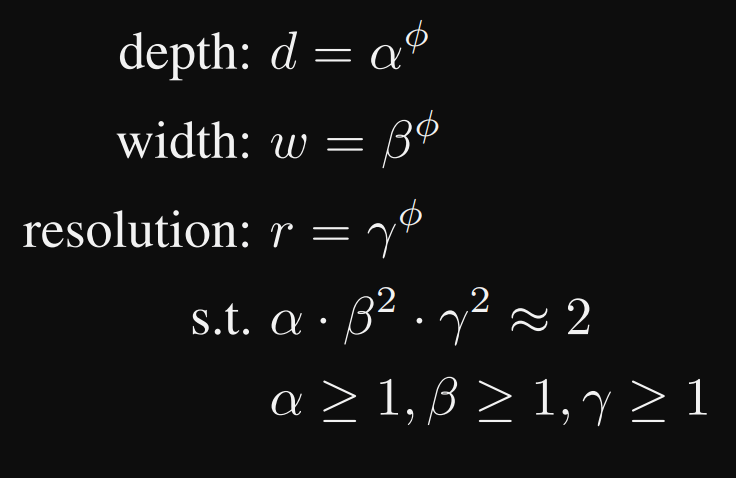
With depth, width and resolution:
Conclusion
This article and the previous one summarized the modern methods used by the best COCO ranking architectures such as Transformers (Swin / Focal), YOLOR, the CBNet and R-CNN series, CenterNet, DetectoRS and EfficientDet. All of these methods were very different, some with a focus on maximizing AP, some on efficiency, and the last one EfficientDet which successfully implemented a scalable network for many different efficiency constraints.

This post answered some doubts I had, much appreciated.
LikeLiked by 1 person